Using AppLinks to link to other applications¶
AppLinks allow you to link applications to each other. Linking two applications allows you to access one application's properties from within the other.
In this tutorial we create an application that provides different datasets. The user can select one of these datasets and gets some information about it. This example can be used as a template for your own applications.
Dataset Analyzer¶
We have a Cloudgene application with the following folder structure:
dataset-analyzer ├── cloudgene.yaml ├── analyze-dataset.groovy ├── datasets | ├── dataset1.csv | └── dataset2.csv └── README.md
In folder datasets we have different datasets and the user can select one of these datasets. For this propose, we create the following cloudgene.yaml file that contains one input parameter of type list:
name: dataset-analyzer version: 1.0 workflow: steps: - name: Analyze Dataset type: groovy script: analyze-dataset.groovy inputs: - id: dataset description: Dataset type: list values: dataset1: Dataset 1 dataset2: Dataset 2
To simulate our analysis pipeline, we create a small groovy script called analyze-dataset.groovy that prints the content of the selected dataset:
import genepi.hadoop.common.WorkflowContext def run(WorkflowContext context) { def dataset = context.get("dataset"); def directory = context.getWorkingDirectory(); def content = ''; switch(dataset){ case 'dataset1': content = new File(directory + '/datasets/dataset1.csv').text; break; case 'dataset2': content = new File(directory + '/datasets/dataset2.csv').text; break; } // annalyze dataset. for demonstration: print content. context.ok(content); return true; }
Next, we can install our application via the commandline and start a Cloudgene server:
cloudgene install dataset-analyzer dataset-analyzer/cloudgene.yaml cloudgene server
If we open http://localhost:8082 in our broswer we can submit a new job for this application:
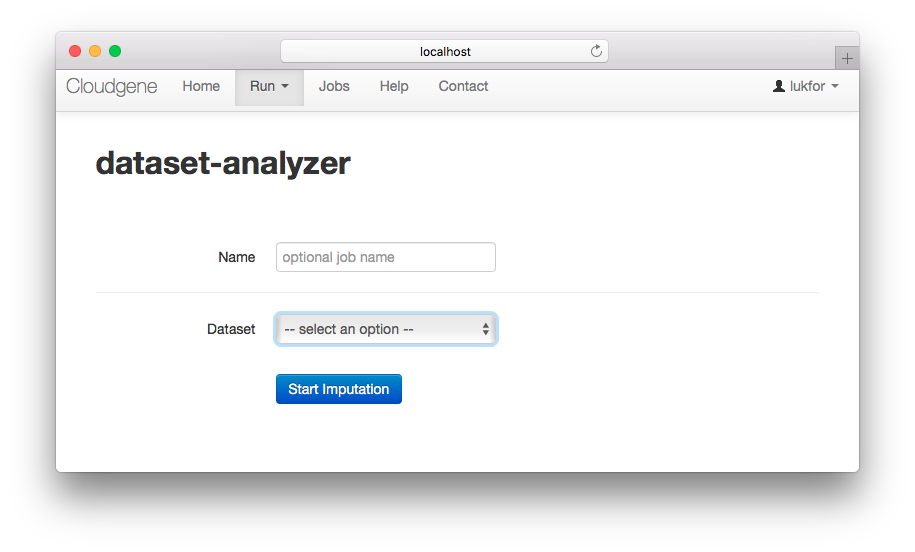
Depending on the selected dataset, we get different outputs:
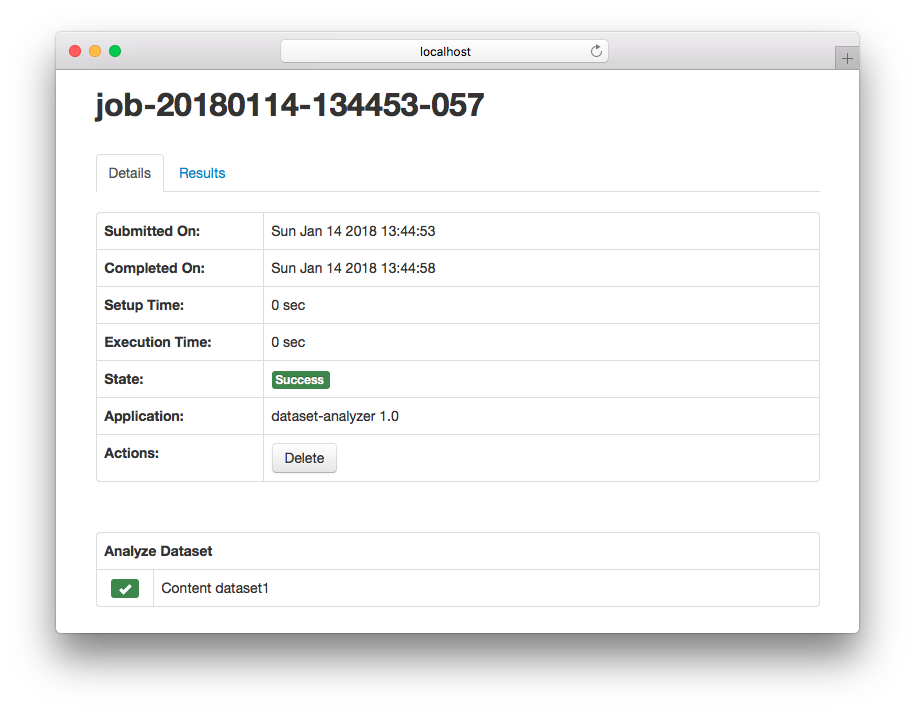
The Cloudgene application works as expected. However, the following implementation has several shortcomings:
- each time we want to add a new dataset, we have to adapt the groovy script and have to change
valuesincloudgene.yaml. - this leads to different
cloudgene.yamlfiles for different setups on different servers - different
cloudgene.yamlfiles are hard to deploy, update and to manage (especially in full automated Cloud deployments)
Switch to AppLinks¶
A more generic solution is to create one application for each dataset. This enables us to separate our application logic from our datasets.
By using AppLinks we have the possibility to link them together and the cloudgene.yaml file of our application stays the same no matters how many new datasets we want to create.
Dataset Application¶
In a first step, we create an application for Dataset1 with the following folder structure:
dataset1 ├── cloudgene.yaml ├── dataset1.csv └── README.md
Next, we create the following cloudgene.yaml file for our dataset:
name: Dataset 1 version: 1.0 category: datasets properties: filename: ${local_app_folder}/dataset1.csv
Our cloudgene.yaml file contains no workflow steps, instead we define properties. This properties can be used to share information from the Dataset application to the Dataset Analyzer application. In this case we define a property that contains the filename of our dataset. Moreover, we use the local_app_folder variable to get the correct directory and to avoid hard-coded paths.
The category property can be used to annotate our different Dataset applications. We give all datasets the same category so we can further filter them when we create an AppLinks list.
Finally, we can create an application for Dataset2 in the same way.
Dataset Analzer Application¶
Now, we can remove all datasets from Dataset-Analyzer application:
dataset-analyzer ├── cloudgene.yaml ├── analyze-dataset.groovy └── README.md
In the cloudgene.yaml file we replace the input type with app_list and add a custom filter to display only applications that fall in category datasets:
name: dataset-analyzer version: 1.0 workflow: steps: - name: Analyze Dataset type: groovy script: analyze-dataset.groovy inputs: - id: dataset description: Dataset type: app_list category: datasets
We adapt our groovy script to read the file from the location we shared through properties. With context.getData(param_id) we get access to all properties of the selected application:
import genepi.hadoop.common.WorkflowContext def run(WorkflowContext context) { def datasetProperties = context.getData("dataset"); def filename = datasetProperties.get('filename'); def content = new File(filename).text; // annalyze dataset. for demonstration: print content. context.ok(content); return true; }
We stop Cloudgene and restart it. When we try to submit a new job, we see that the list of datasets is empty.
Therefore, we stop Cloudgene again and install dataset1:
cloudgene install dataset1 dataset1/cloudgene.yaml cloudgene server
Now, when we open the submit dialog of Dataset-Analyzer, we see Dataset1 and when we start the job we get the expected output.
- screenshot
Advantages¶
- we don't need to change our application when we want to add a new dataset
- we have a simple and straightforward way to create new datasets
- its very easy to share datasets and to install them (independently from the application)
- admin has full control of permissions: access to specific datasets can be managed by user groups